All about Git and GitHub
Introduction
The blog is created with an intention to help those who are new to the programming world and has a little or no idea about what Git and Github actually is.
Disclaimer: The content in this blog is taken from various sources. The main objective is to give audience a platform where they can read everything related the Git and do not search for multiple websites for understanding different topics.
Topics to be discussed:
- What is Git
- What is GitHub
- How to create a GitHub account
- How to create a new repository ( discussion of two methods to create a repo)
- Basic Git commands ( init, add, push, status, push, log, ignore, reset, branch, merge, fork, pull, fetch)
- Undo changes in Git (reset)
- Working with groups ( branching and forking)
- Other benefits of using GitHub: Raise an Issue
What is Git ?
Git is a free, open source distributed version control system. Now that’s a lot of words to define Git.
Let me break it down and explain the wording:
Control System: This basically means that Git is a content tracker. So Git can be used to store content — it is mostly used to store code due to the other features it provides.
Version Control System (VCS):
The code which is stored in Git keeps changing as more code is added. So Version Control System helps in handling this by maintaining a history of what changes have happened.

Distributed Version Control System:
In software development, distributed version control is a form of version control in which the complete codebase, including its full history, is mirrored on every developer’s computer. (Wikipedia)

Note: The centralized VCS keep the history of changes on a central server from which everyone requests the latest version of the work and pushes the latest changes to. On the other hand, on a distributed VCS, everyone has a local copy of the entire work’s history.

Git has a remote repository which is stored in a server and a local repository which is stored in the computer of each developer. This means that the code is not just stored in a central server, but the full copy of the code is present in all the developers’ computers. Git is a Distributed Version Control System since the code is present in every developer’s computer.
For e.g., if you want to make a change it can be done right there on your system. Later once you have a few changes done, you can upload your changes to the central server for all the team members to use. Similarly, if you want to see the history of changes made to a project you don’t need a network connection. All the changes can be viewed from your local copy only.
What is Github?
GitHub is a Git repository hosting service. It takes that change history made by you so far in your code and hosts it online so that you can access it from any computer. You do this via pushing changes from your local machine (i.e.: the computer you’re currently using) up to Github, and then, from the new/different computer pulling those changes down.

The purpose of Git is to manage a project, or a set of files, as they change over time. Git stores this information in a data structure called a repository. A git repository contains, among other things, the following: A set of commit objects. A set of references to commit objects, called heads.
Commit Objects
A commit object contains three things:
- A set of files, reflecting the state of a project at a given point in time.
- References to parent commit objects.
- An SHA1 name, a 40-character string that uniquely identifies the commit object. The name is composed of a hash of relevant aspects of the commit, so identical commits will always have the same name.
The parent commit objects are those commits that were edited to produce the subsequent state of the project. Generally a commit object will have one parent commit, because one generally takes a project in a given state, makes a few changes, and saves the new state of the project. The section below on merges explains how a commit object could have two or more parents.
A project always has one commit object with no parents. This is the first commit made to the project repository.
Based on the above, you can visualise a repository as a directed acyclic graph of commit objects, with pointers to parent commits always pointing backwards in time, ultimately to the first commit. Starting from any commit, you can walk along the tree by parent commits to see the history of changes that led to that commit.
The idea behind Git is that version control is all about manipulating this graph of commits. Whenever you want to perform some operation to query or manipulate the repository, you should be thinking, “how do I want to query or manipulate the graph of commits?”
Heads
A head is simply a reference to a commit object. Each head has a name. By default, there is a head in every repository called master. A repository can contain any number of heads. At any given time, one head is selected as the “current head.” This head is aliased to HEAD, always in capitals.
Note this difference: a “head” (lowercase) refers to any one of the named heads in the repository; “HEAD” (uppercase) refers exclusively to the currently active head. This distinction is used frequently in Git documentation. I also use the convention that names of heads, including HEAD, are set in italics.
Create a GitHub Account
- Go to the following website: https://github.com/
- Select a username, email-id and password for your account and press the Sign up button on the right corner.

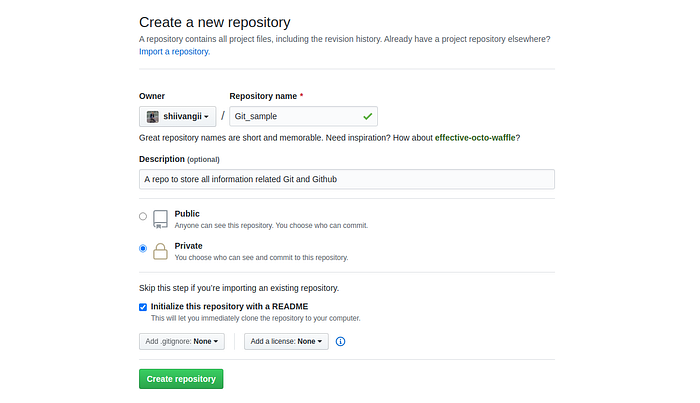
Create a repository on GitHub
- A new repository from scratch
There are two ways for creating repository.
Method 1:
mkdir [project]
cd [project]
git init
git add .
git commit -m 'initial commit' --allow-empty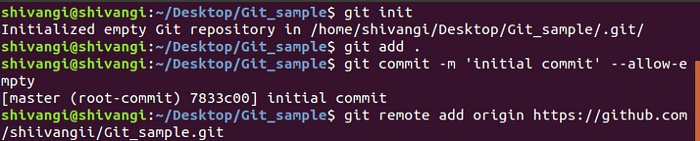
You’ve now got a local git repository. You can use git locally, like that, if you want. But if you want the thing to have a home on github, do the following.
- Go to GitHub.
- Log in to your account.
- Click the new repository button in the top-right. You’ll have an option there to initialize the repository with a README file, but I don’t.
- Click the “Create repository” button.
Now, follow the second set of instructions, “Push an existing repository…”
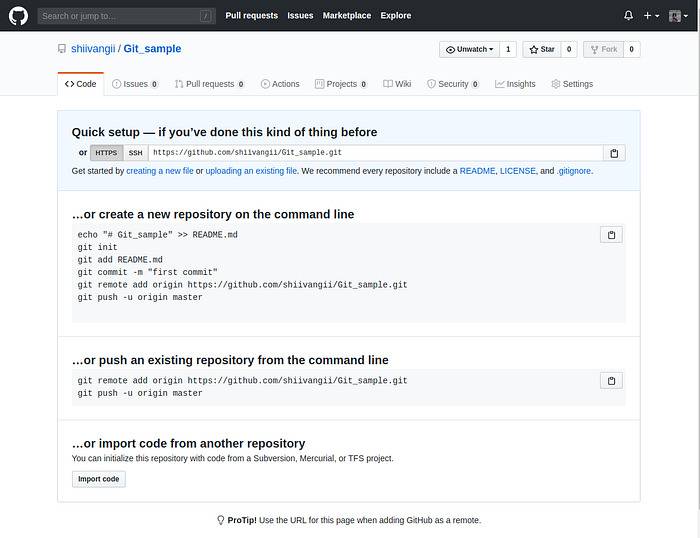
git remote add origin https://github.com/USERNAME/FOLDER-NAME.git
git push -u origin master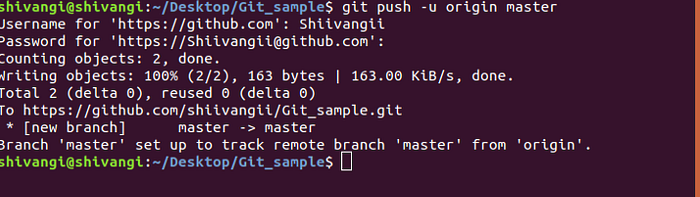
An Important Tip !!!
Sometimes you might encounter errors (mentioned below) while pushing an existing repository from command line.
git push -u origin master
error: src refspec master does not match any.Therefore to avoid that error, we use the following command :
$ git commit -m "initial commit" --allow-empty
...
$ git push -u origin master
...One of main reasons of this problem is that some Git servers, such as GitHub, don't have their master branch initialised when a fresh repository is cloned.
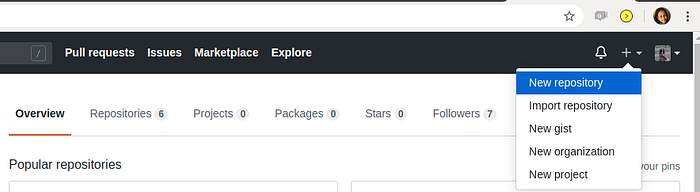
Method 2:
- Login to your GitHub Account
- Look for + sign in right corner, press it. Drag to the option where it is mention New repository.
3. Fill in all the details and your repository is created.
A README is often the first item a visitor will see when visiting your repository. README files typically include information on:
- What the project does
- Why the project is useful
- How users can get started with the project
- Where users can get help with your project
- Who maintains and contributes to the project
4. Clone the repository locally.
- copy the clone address shown below.
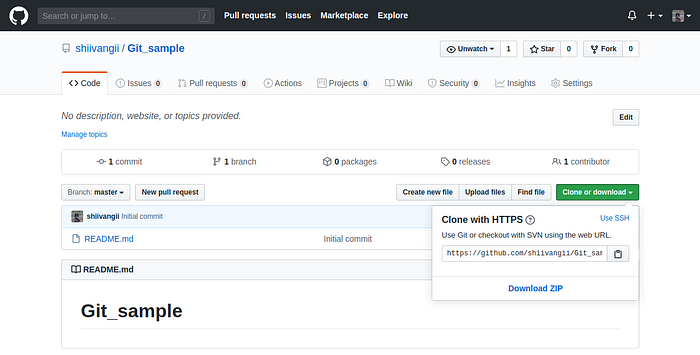
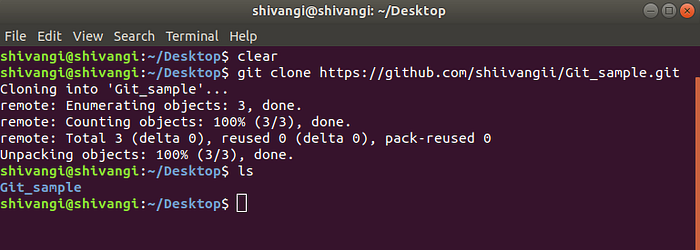
- write on Terminal:
git clone https://github.com/username/repository_name.git
Some Basic Git commands
- git init
The git init command creates a new Git repository. It can be used to convert an existing, unversioned project to a Git repository or initialize a new, empty repository. Most other Git commands are not available outside of an initialized repository, so this is usually the first command you'll run in a new project.
2. git clone
If a project has already been set up in a central repository, the git clone command is the most common way for users to obtain a development copy. Like git init, cloning is generally a one-time operation. Once a developer has obtained a working copy, all version control operations and collaborations are managed through their local repository.
git init vs. git clone
A quick note: git init and git clone can be easily confused. At a high level, they can both be used to "initialize a new git repository." However, git clone is dependent on git init. git clone is used to create a copy of an existing repository. Internally, git clone first calls git init to create a new repository. It then copies the data from the existing repository, and checks out a new set of working files.
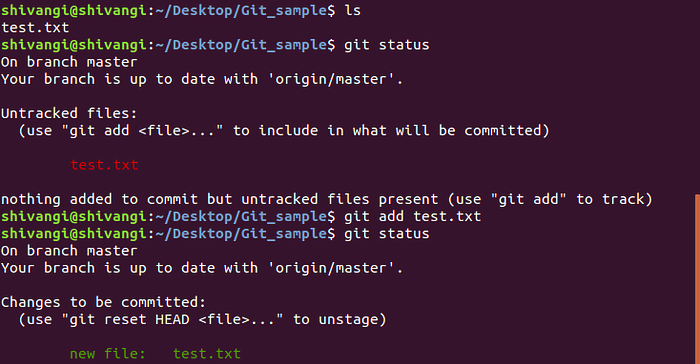
3. git add
The git add command adds a change in the working directory to the staging area. It tells Git that you want to include updates to a particular file in the next commit. However, git add doesn't really affect the repository in any significant way—changes are not actually recorded until you run git commit.
4. git status
The git status command is used to examine the current state of the repository and can be used to confirm a git add promotion.
5. git commit
The git commit command is then used to Commit a snapshot of the staging directory to the repositories commit history.
-m <message>
Sets the commit’s message. Make sure to provide a concise description that helps your teammates (and yourself) understand what happened.
-a
Includes all currently changed files in this commit. Keep in mind, however, that untracked (new) files are not included.
— amend
Rewrites the very last commit with any currently staged changes and/or a new commit message. Git will rewrite the last commit and effectively replace it with the amended one. Note that such a rewriting of commits should only be performed on commits that have not been pushed to a remote repository, yet.

6. git push
The git push command is used to upload local repository content to a remote repository. Pushing is how you transfer commits from your local repository to a remote repo.
git push <remote> <branch>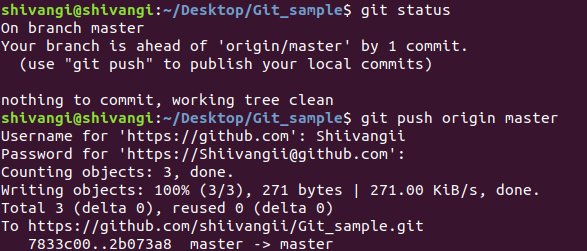
Undo Changes in Git
7. git log
The whole idea behind any version control system is to store “safe” copies of a project so that you never have to worry about irreparably breaking your code base. Once you’ve built up a project history of commits, you can review and revisit any commit in the history. One of the best utilities for reviewing the history of a Git repository is the git log command.
Each commit has a unique SHA-1 identifying hash. These IDs are used to travel through the committed timeline and revisit commits. By default, git log will only show commits for the currently selected branch.

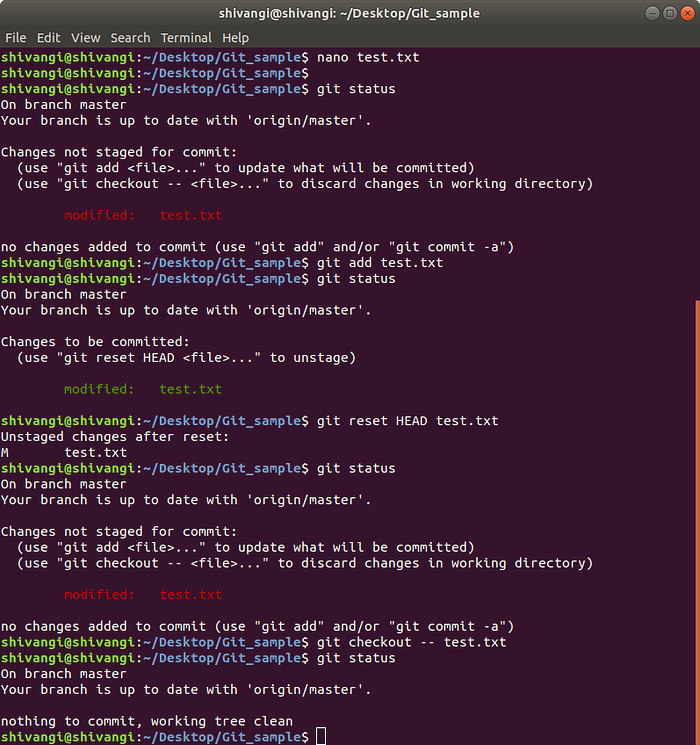
Undoing unstaged changes
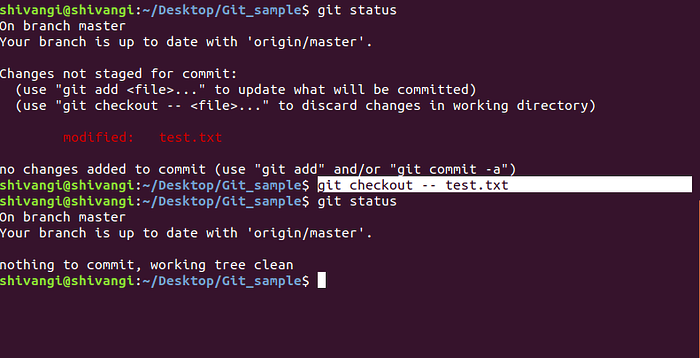
If a file has been changed, but these changes have not yet been staged with git add, then the changes can be undone using git checkout. The instructions for using git checkout to undo changes are described in the output of git status (highlighted in white color).
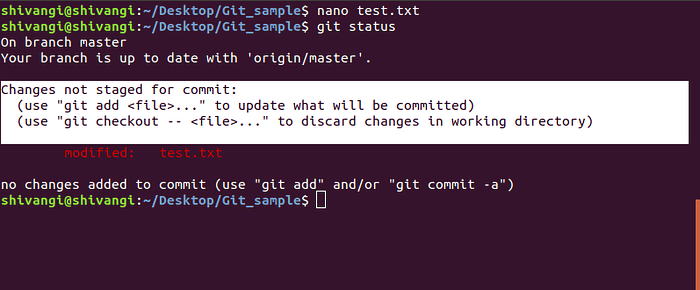
The output from git status tells you that you can use git checkout -- <file> to discard changes to that file in your repo.
Unstaging staged changes
Remember that once you add a set of changes to git using git add, the file is then staged. If a file has been changed and then staged via git add, then you use git reset to pull the most recently committed version of the file and undo the changes that you’ve made.
Fortunately, the output of git status gives us a hint for how to undo our staged changes:
You use git reset HEAD <file> to unstage our changes. HEAD refers to the most recently committed version of the file.
When you use git reset, your changes still exist in the file, but the file has been unstaged (the changes are not added to git, yet).
Now that you have changes that are not staged, you can use git checkout to undo those modifications. Git reset is essentially the opposite of the command git add. It undoes the add.
What is staging and Unstaging in git?
The staging area (aka index) is a container where git collects all changes which will be part of the next commit. If you are editing a versioned file on your local machine, git recognises that your file is modified — but it will not be automatically part of your next commit and is therefore unstaged.
Undoing a commit
If you have modified, added and committed changes to a file, and want to undo those changes, then you can again use git reset HEAD~ to undo your commit. Similar to the previous example, when you use git reset the modifications will be unstaged.
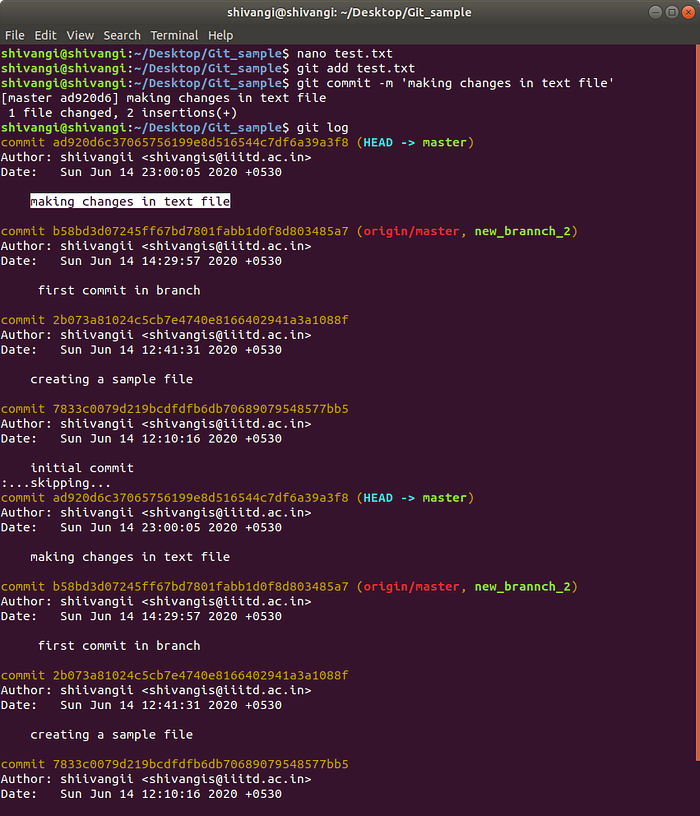
Notice that now your file is no longer being tracked!
If you inspect the output of git log, you will notice that your previous commit is no longer part of the repository’s history.

Ignore sensitive files
If you do have sensitive files in a repository that you never want to track with git, you can add those file names to a file called .gitignore, and git will not track them.
Any files listed in this file will be ignored by git. You can also tell git to ignore entire directories.
Working with Groups
There can be different ways to work on a single project with multiple people involved. Suppose, a team of engineers are working on building a product. Team consists of three members. The different options to use git are as follows:
BRANCHING
Each team member creates a branch of the master project and on completion, perform the merging of the two branches (i.e. one created by him and the master branch).
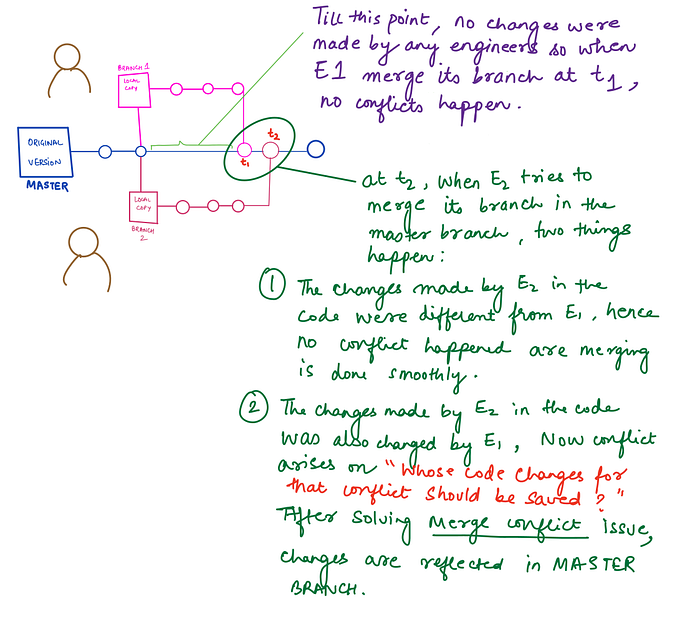
Branching in Git
The default branch name in Git is master.
Why we need branches in a Git repo ?
The main reasons for having branches are:
- If you are creating a new feature for your project, there’s a reasonable chance that adding it could break your working code. This would be very bad for active users of your project. It’s better to start with a prototype, which you would want to design roughly in a different branch and see how it works, before you decide whether to add the feature to the repo’s
masterfor others to use. - Another, probably more important, reason is Git was made for collaboration. If everyone starts programming on top of your repo’s
masterbranch, it will cause a lot of confusion. Everyone has different knowledge and experience (in the programming language and/or the project); some people may write faulty/buggy code or simply the kind of code/feature you may not want in your project. Using branches allows you to verify contributions and select which to add to the project. (This assumes you are the only owner of the repo and want full control of what code is added to it. In real-life projects, there are multiple owners with the rights to merge code in a repo.)
Create a branch in Git
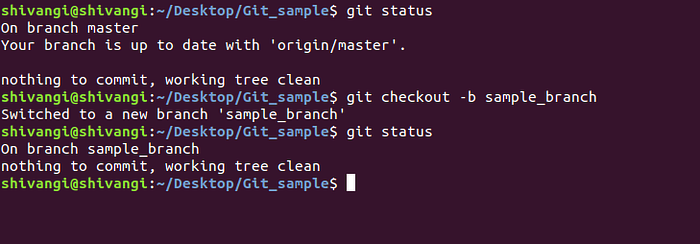
git status
git checkout -b sample_branch
git statusThe first command, git status reports you are currently on branch master, and (as you can see in the terminal screenshot below) it is up to date with origin/master, which means all the files you have on your local copy of the branch master are also present on GitHub. There is no difference between the two copies. All commits are identical on both the copies as well.
The next command, git checkout -b sample_branch, -b tells Git to create a new branch and name it sample_branch, and checkout switches us to the newly created branch. Enter the third line, git status, to verify you are on the new branch you just created.
As you can see below, git status reports you are on branch sample_branch and there is nothing to commit. This is because there is neither a new file nor any modification in existing files.
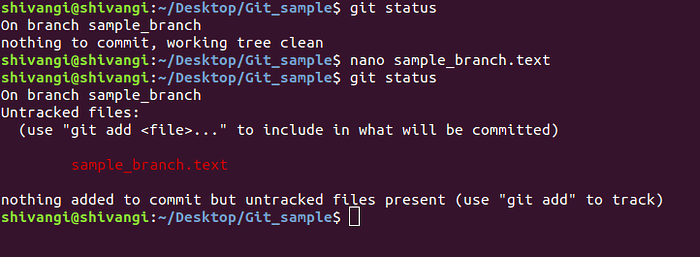
nano sample_branch.txt
git statusThe first command, nano, creates a file named sample_branch.txt, and saves what is written in it. git status tells you the current status of our branch sample_branch. In the terminal screenshot below, Git reports there is a file called sample_branch.txt on sample_branch and sample_branch.txt is currently untracked. That means Git has not been told to track any changes that happen to sample_branch.txt.
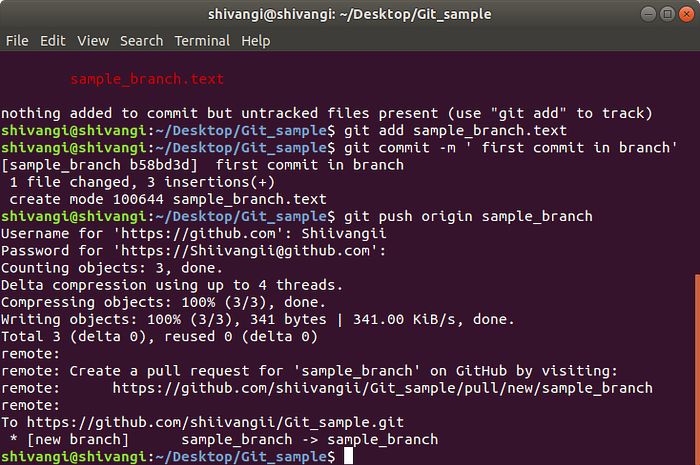
The next step is to add, commit, and push newFile to myBranch (go back to the last article in this series for more details).
git add sample_branch.txt
git commit -m "first commit in branch"
git push origin sample_branchIn these commands, the branch in the push command is sample_branch instead of master. Git is taking newFile, pushing it to your Demo repository in GitHub, and telling you it's created a new branch on GitHub that is identical to your local copy of sample_branch. The terminal screenshot below details the run of commands and its output.
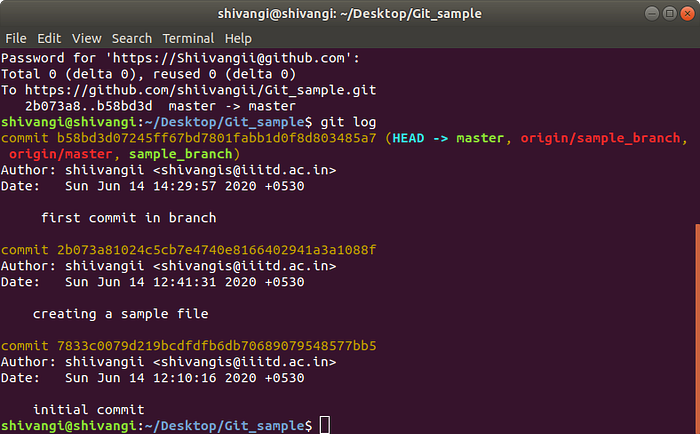
Merging branches
git checkout master
git merge sample_branch
git push origin master
After running the above commands, the merge should be successful. In this example, there are no conflicts.
But in real projects, there will be conflicts when a merge is being done. Resolving the conflict is something which comes with experience, so as you work more with Git you will be able to get the hang of resolving conflicts.
Run git log now and you will notice that the master also has 3 commits.
Delete a branch in Git
1. Delete the local copy of your branch: Since you can’t delete a branch you’re on, switch to the master branch (or another one you plan to keep) by running the following below mentioned commands.
git branch
git checkout master
git branch -D sample_branch
git push 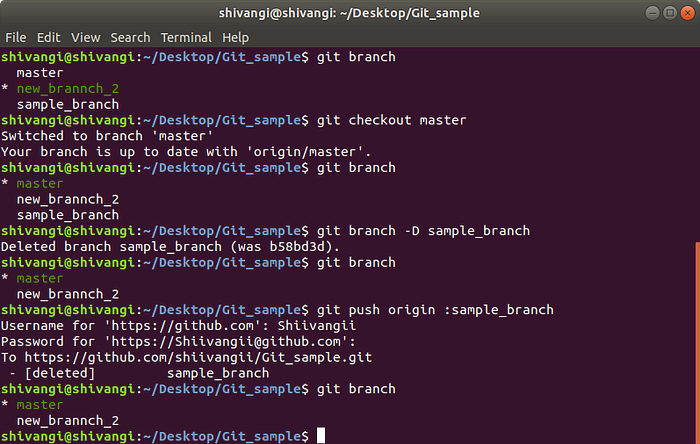
git branch lists the available branches; checkout changes to the master branch and git branch -D removes that branch. Run git branch again to verify there are now only two branches (instead of three).
2. Delete the branch from GitHub
Delete the remote copy of sample by running the following command:
git push origin :sample_branchThe colon (:) before the branch name in the push command tells GitHub to delete the branch. Another option is:
git push -d origin sample_branchas -d (or --delete) also tells GitHub to remove your branch.
FORKING
The Forking Workflow begins with an official public repository stored on a server. But when a new developer wants to start working on the project, they do not directly clone the official repository.
Instead, they fork the official repository to create a copy of it on the server. This new copy serves as their personal public repository — no other developers are allowed to push to it, but they can pull changes from it (we’ll see why this is important in a moment). After they have created their server-side copy, the developer performs a git clone to get a copy of it onto their local machine. This serves as their private development environment, just like in the other workflows.
When they’re ready to publish a local commit, they push the commit to their own public repository — not the official one. Then, they file a pull request with the main repository, which lets the project maintainer know that an update is ready to be integrated. The pull request also serves as a convenient discussion thread if there are issues with the contributed code. The following is a step-by-step example of this workflow.
- A developer ‘forks’ an ‘official’ server-side repository. This creates their own server-side copy.
- The new server-side copy is cloned to their local system.
- A Git remote path for the ‘official’ repository is added to the local clone.
- A new local feature branch is created.
- The developer makes changes on the new branch.
- New commits are created for the changes.
- The branch gets pushed to the developer’s own server-side copy.
- The developer opens a pull request from the new branch to the ‘official’ repository.
- The pull request gets approved for merge and is merged into the original server-side repository
To integrate the feature into the official codebase, the maintainer pulls the contributor’s changes into their local repository, checks to make sure it doesn’t break the project, merges it into their local master branch, then pushes the master branch to the official repository on the server. The contribution is now part of the project, and other developers should pull from the official repository to synchronise their local repositories.
Difference between Forking and Cloning
What are the major differences between Forking and Cloning?
To clear out the air from your mind, if you have any, let see how these two terms differ:
- Forking is done on the GitHub Account while Cloning is done using Git. When you fork a repository, you create a copy of the original repository (upstream repository) but the repository remains on your GitHub account. Whereas, when you clone a repository, the repository is copied on to your local machine with the help of Git.
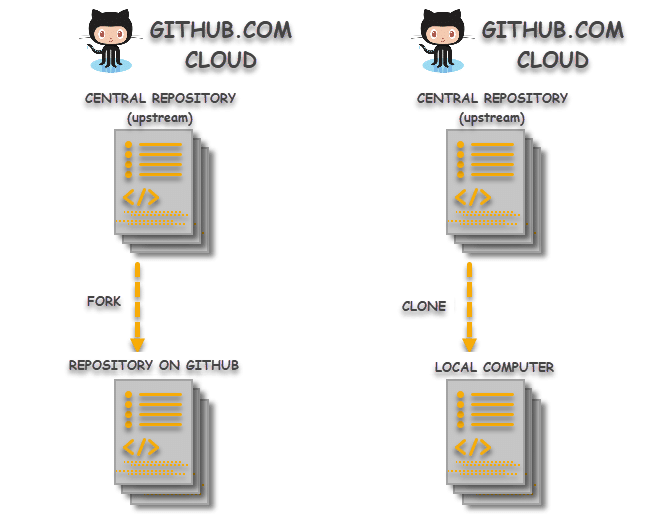
- Changes made to the forked repository can be merged with the original repository via a pull request. Pull request knocks the repository owner and tell that “I have made some changes, please merge these changes to your repository if you like it”. On the other hand, changes made on the local machine (cloned repository) can be pushed to the upstream repository directly. For this, the user must have the write access for the repository otherwise this is not possible. If the user does not have the write access, the only way to go is through the forked request. So in that case, the changes made in the cloned repository are first pushed to the forked repository and then a pull request is created. It is a better option to fork before clone if the user is not declared as a contributor and it is a third party repository (not of the organization).
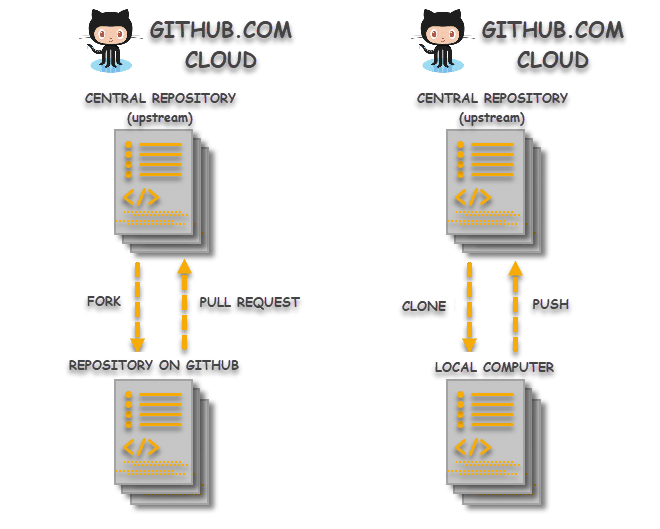
- Forking is a concept while cloning is a process. Forking is just containing a separate copy of the repository and there is no command involved. Cloning is done through the command ‘git clone‘ and it is a process of receiving all the code files to the local machine.
How Cloning Works
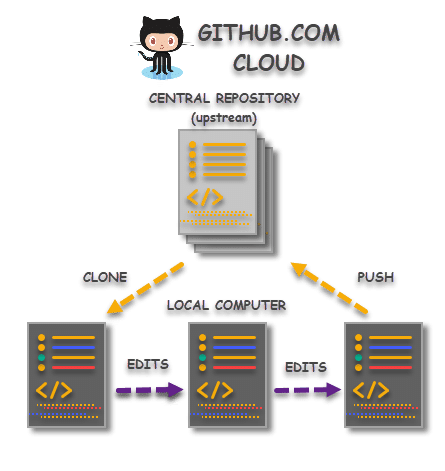
- Step 1: Clone a Repository: The user starts from the upstream repository on GitHub. Since the user navigated to the repository because he/she is interested in the concept and they like to contribute. This process starts from cloning when they clone the repository it into their local machine. Now they have the exact copy of the project files on their system to make the changes.
- Step 2: Make the desired changes: After cloning, contributors provide their contribution to the repository. Contribution in the form of editing the source files resulting in either a bug fix or adding functionality or maybe optimizing the code. In this step, a contributor can apply a single commit or multiple commits to the repository. But the bottom line is, everything happens on their local system.
- Step 3: Pushing the Changes: Once the changes or commits are done and now the modifications can be pushed to the upstream repository.
How Forking works
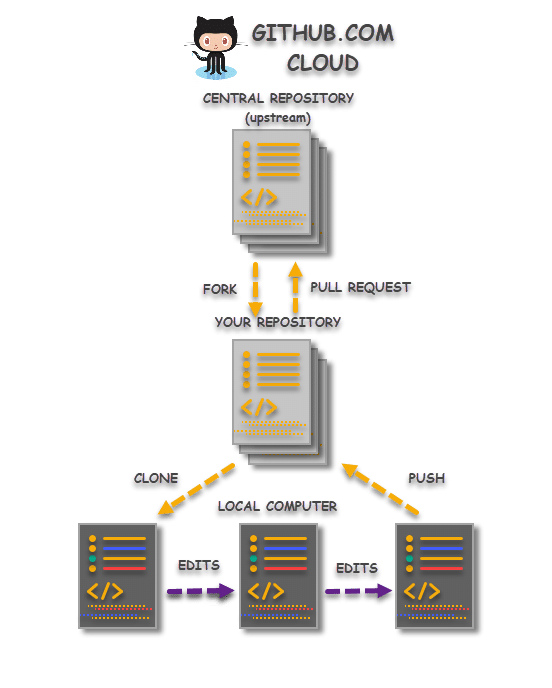
- Step 1: Fork a Repository: Again the user starts from the upstream repository on GitHub but this process starts from forking when they fork a repository to their own GitHub account.
- Step 2: Clone a Repository: Same as cloning.
- Step 3: Make the desired changes: Same as cloning.
- Step 4: Pushing the Changes: Same as cloning.
- Step 5: Send changes to Original Repository: This process is called Pull Request in Git. At this step, the user sends the changes to the owner of the repository as a request to merge the changes to the main central repository.
Git Pull
The git pull command is used to fetch and download content from a remote repository and immediately update the local repository to match that content.
Git Pull assumes that any change that has occurred in the repository requires merging.
Git Fetch
When you do a git fetch, it fetches all the changes from the remote repository and stores it in a separate branch in your local repository. You can reflect those changes in your corresponding branches by merging. So basically, git pull = git fetch + git merge.
Difference between Git Pull and Git Fetch
To understand the differences between fetch and pull, let’s know the similarities between both of these commands. Both commands are used to download the data from a remote repository. But both of these commands work differently. Like when you do a git pull, it gets all the changes from the remote or central repository and makes it available to your corresponding branch in your local repository. When you do a git fetch, it fetches all the changes from the remote repository and stores it in a separate branch in your local repository. You can reflect those changes in your corresponding branches by merging.
Or in another words, using git fetch is often the case when someone else is also working with you on the same branch. The scenario might look like your friend will ask you to look at some changes they have done on the branch and merge if you like it. Now since you are not sure enough about the merging of the changes, you will first fetch these changes, review them, and then merge. We use Git pull when one is working alone on the branch. Since there is no point in reviewing your changes again, you can directly pull them to your repository.
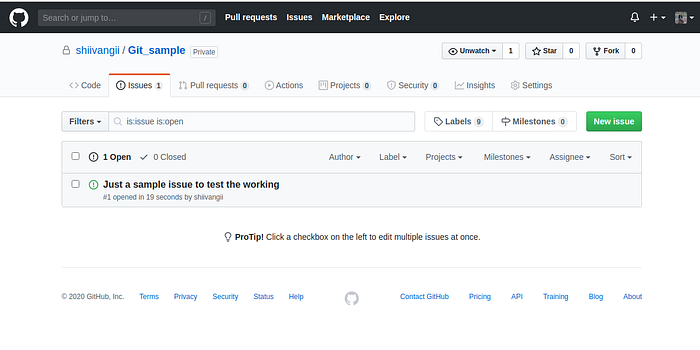
How to open a Git Issue
- Go to the project you want to raise issue on.
- Press Issues button available on Left side of GitHub screen.
- Press New Issue button available in green on right side of screen.
- Enter your query and label it accordingly.

5. After raising press the Submit new issue button and you are done.